We Go Fast,You Go Forward
May 25, 2026
Nanopore sequencing has emerged as one of the most transformative technologies in modern genomics. By passing individual DNA or RNA molecules through tiny protein pores and measuring disruptions in electrical current, it delivers long reads in real time without the need for fluorescent labels or extensive amplification. Developed by Oxford Nanopore Technologies, this platform stands out for its portability, speed, and ability to sequence native molecules directly. At Quintara Bio, we leverage the latest nanopore chemistry to offer fast, reliable sequencing services tailored to researchers, clinicians, and biotech teams across the United States.
Whether you need rapid plasmid verification, full-length transcript analysis, or complex metagenomic profiling, nanopore sequencing opens new possibilities that short-read platforms often cannot match.
Nanopore sequencing is a third-generation sequencing method that reads DNA and RNA at the single-molecule level by detecting changes in ionic current as nucleic acids pass through a biological nanopore. Unlike second-generation technologies that rely on synthesis and optical detection, it measures electrical signals in real time, producing reads that can span tens to hundreds of thousands of bases — and occasionally even millions.
It belongs firmly to the third-generation category because it sequences single molecules without clonal amplification in many workflows. This preserves natural epigenetic modifications such as DNA methylation, which are frequently lost or distorted in PCR-based methods. Core features include:
· Single-molecule sequencing — No need to create clonal clusters.
· PCR-free options — Reduces bias and maintains native molecule integrity.
· Real-time sequencing — Data streams live, allowing researchers to monitor progress and stop runs early when sufficient coverage is reached.
In contrast to traditional Sanger or Illumina sequencing, which break genomes into short fragments and reassemble them computationally with potential gaps in repetitive regions, nanopore sequencing provides long, contiguous reads that simplify assembly and resolve complex structural variants. This makes it particularly valuable for de novo genome projects, pathogen surveillance, and clinical applications where speed and completeness matter.
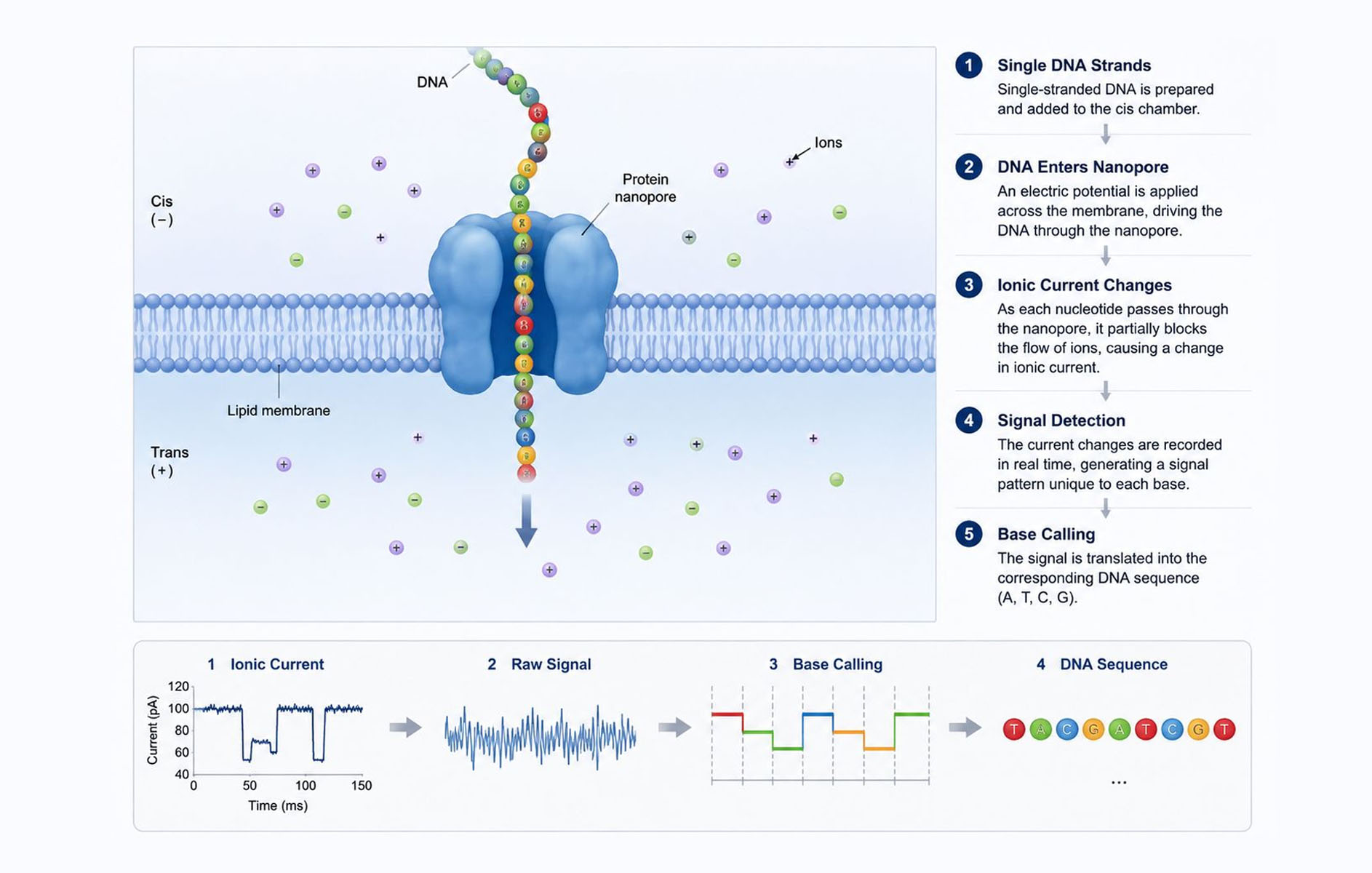
The elegance of nanopore sequencing lies in its straightforward biophysical principle, unfolding in four main steps that occur continuously.
A flow cell holds an electro-resistant synthetic membrane embedded with thousands to millions of protein nanopores (currently R10.4.1 chemistry). Each nanopore sits above its own sensor on a chip. An electric voltage applied across the membrane drives ions through the open pore, creating a steady baseline current.
During library preparation, motor proteins (such as helicases) are attached to the nucleic acid molecules. These proteins control the speed at which the single-stranded molecule threads through the nanopore under the influence of the electric field. The motor ratchets the molecule at a controlled pace — typically around 400–500 bases per second in modern kits — preventing it from zipping through too quickly.
As each base or short k-mer (usually 5–9 bases) occupies the narrow constriction of the nanopore, it partially blocks ion flow, causing a characteristic drop or change in the electrical current. Different nucleotides produce distinct signal patterns due to their unique size, shape, and charge. The result is a continuous "squiggle" trace — raw electrical data captured at high frequency.
Sophisticated AI algorithms (such as Dorado with super-accurate SUP models) decode the raw squiggles into the familiar A, C, G, and T (or U for RNA) sequence in real time. Modern chemistry also enables simultaneous detection of base modifications like methylation without additional library steps.
This process delivers real-time sequencing, with usable data appearing within minutes of starting a run. The entire workflow emphasizes flexibility: rapid library kits can be prepared in as little as 10 minutes, making the technology ideal for time-sensitive projects.
Several integrated components make the system both powerful and scalable:
· Flow cell — The disposable consumable containing the membrane and nanopore array. Different sizes support everything from pocket-sized MinION to high-throughput PromethION instruments.
· Nanopores — Engineered transmembrane proteins (R10.4.1 is the current standard) that serve as the sensing element.
· Motor protein — Guides and slows the nucleic acid, ensuring clear signal resolution.
· Sensor chip and electrodes — Detect picoamp-level current changes with high precision.
· Basecalling software — Converts raw PODS signal files into FASTQ sequences, often running locally or in the cloud.
Devices range from the highly portable MinION Mk1D (USB-powered) to benchtop and production-scale systems. At Quintara Bio, we optimize these components with the latest kits to maximize yield and accuracy for client samples.
Nanopore sequencing excels in scenarios where traditional methods struggle:
· Real-time analysis — Monitor data as it generates and make decisions on the fly — critical during infectious disease outbreaks or clinical diagnostics.
· Long and ultra-long reads — Average reads of 10–30 kb are common, with records exceeding 4 Mb. This dramatically improves genome assembly, haplotype phasing, and detection of structural variants.
· Direct native sequencing — PCR-free workflows preserve epigenetic information and reduce amplification bias.
· Portability — The MinION has been deployed in remote field sites, on the International Space Station, and even in hospital settings for bedside sequencing.
· Epigenetic detection — Native molecules allow simultaneous calling of methylation and other modifications.
These strengths make nanopore the preferred choice for de novo assemblies, full-length RNA isoform analysis, metagenomics of complex communities, and rapid pathogen identification.
Like any technology, nanopore sequencing has trade-offs that continue to improve with each chemistry release:
· Accuracy — Earlier generations had higher error rates, particularly in homopolymer regions. With R10.4.1 chemistry and SUP basecalling, single-read (simplex) accuracy now routinely exceeds 99% (Q20+), while duplex reads can reach Q30 (>99.9%) in optimal conditions.
· Signal noise — Certain sequence contexts still require higher coverage or hybrid approaches for perfect consensus.
· Data analysis complexity — Raw signal files are large, and robust bioinformatics pipelines are needed, though user-friendly tools and cloud options have simplified this significantly.
Ongoing advances in pores, enzymes, and AI models are rapidly narrowing the remaining gaps. At Quintara Bio, our experienced team handles these nuances so clients receive clean, publication-ready data.
Real-world applications highlight why nanopore sequencing has gained widespread adoption:
Rapid detection of pathogens, tracking antimicrobial resistance, and identifying structural variants in cancer genomes. Same-day results for plasmids and amplicons are especially valuable in synthetic biology and quality control.
Metagenomic sequencing of environmental or clinical samples without culturing. During outbreaks, portable devices enable on-site genome sequencing for real-time variant surveillance.
De novo assembly of large or repetitive genomes (plants, animals, polyploids) benefits enormously from ultra-long reads that span difficult regions.
Full-length RNA sequencing captures complete isoforms, alternative splicing, and fusion transcripts that short-read methods often fragment.
Direct methylation calling supports studies in development, disease, and environmental response.
At Quintara Bio, we specialize in making these applications accessible. Our nanopore services include whole plasmid sequencing (up to 25 kb with same-day turnaround), amplicon sequencing starting at competitive rates, full-length transcript sequencing, metagenomics, and de novo whole genome sequencing. Submit your samples and let our team handle library preparation, sequencing on the latest Oxford Nanopore platforms, and comprehensive bioinformatics analysis.
Speed remains one of its standout advantages:
· Library preparation: As little as 10–60 minutes with rapid kits; a few hours for more complex protocols.
· Sequencing: Data begins streaming within minutes of loading the flow cell.
· Real-time insights: Many applications yield actionable results in 30 minutes to several hours.
· Full run: Typically 6–72 hours, but runs can be stopped early once coverage goals are met
This real-time capability is unmatched by batch-oriented short-read platforms, enabling faster iteration in research and diagnostics.
The choice between platforms depends on project goals. Here is a practical side-by-side comparison based on current performance:
Dimension | Nanopore Sequencing | Illumina Sequencing |
Read Length | Long to ultra-long (10 kb – 4 Mb+) | Short (typically 75–300 bp) |
Accuracy | >99% simplex (Q20+); >99.9% duplex (Q30+) with latest chemistry | >99.9% (Q30+) per base |
Speed | Real-time; data from minutes | Batch processing; hours to days |
Throughput | Scalable from portable to population scale | Extremely high per run |
Portability | Excellent (USB-powered devices) | Lab-based instruments |
Best For | Genome assembly, structural variants, epigenetics, field work, real-time analysis | High-precision variant calling, large-scale counting applications |
Cost Structure | Flexible entry; strong value for long-read projects | Low per-base cost at very high scale |
Hybrid workflows that combine Illumina's accuracy with nanopore's contiguity are increasingly common and often deliver the best overall results.
"Next-generation sequencing" (NGS) is frequently used as an umbrella term but technically refers to second-generation short-read platforms like Illumina. Nanopore sequencing is a clear third-generation (TGS) technology because it sequences single molecules in real time without amplification or synthesis-by-ligation/synthesis. This fundamental difference allows it to capture long-range genomic information that short-read NGS cannot provide natively.
The technology continues to evolve rapidly. Accuracy has climbed steadily toward Q50 levels in consensus sequences, AI-driven basecalling keeps improving, and clinical regulatory pathways are opening for diagnostic use. Expect even smaller devices, higher yields, seamless multi-omic integration, and broader adoption in precision medicine, conservation biology, and beyond. Oxford Nanopore's iterative model ensures steady innovation, and service providers like Quintara Bio remain at the forefront by implementing the newest chemistries for clients.
Yes — many standard workflows sequence native molecules directly, preserving modifications and minimizing bias. PCR-based options are available when higher input or specific amplification is needed.
Requirements are modest — often 10–100 ng for standard libraries, with optimized kits supporting even lower inputs.
A short overlapping stretch of 5–9 bases whose combined electrical signature is measured and decoded by basecalling software into the final sequence.
Absolutely. Native sequencing captures methylation and other base modifications in the same run without bisulfite conversion or extra steps.
Growing evidence and validation support its use in infectious disease, oncology, and pharmacogenomics, especially where long reads and speed provide critical advantages.
Nanopore sequencing continues to redefine genomics by combining long reads, real-time output, and remarkable flexibility. At Quintara Bio, our US-based team makes this powerful technology accessible with fast turnaround, competitive pricing, and expert support — from same-day plasmid sequencing starting at low per-sample rates to full-scale genomic projects.
Ready to explore how nanopore sequencing can accelerate your research? Contact Quintara Bio today for a consultation or to submit samples. Our experienced scientists are here to help you get the most from every run.
At Quintara Bio, we combine cutting-edge nanopore technology with fast turnaround, competitive pricing, and dedicated customer support. Whether you need Whole Plasmid Sequencing or Amplicon Sequencing, our WPS and Amp series services are designed to move your projects forward quickly and reliably.
Current Promotions
· 5 Free Samples on AmpValue Nanopore Sequencing (code: AmpValue5Free)
· Amplicon Sequencing Clean Up at only $1 per sample (code: Cleanup1)
Submit your samples today through our QuinGo online portal and receive high-quality long-read data with confidence.
Order Now or Contact Us to discuss your custom project. Our team is ready to help you harness the power of nanopore sequencing.
We Go Fast, You Go Forward
![]() sales.us@quintarabio.com
sales.us@quintarabio.com
Quintara Biosciences © 2025 All Rights Reserved | Site Map | Terms of Use | Privacy Policy